Next.js 없이 React와 AWS 서비스들로 직접 SSR 환경을 구축해본 경험기
검색 엔진 최적화(SEO)를 위해 SSR(Server-Side Rendering)은 선택이 아닌 필수였다. 대부분의 검색 엔진 크롤러는 JavaScript로 렌더링되는 콘텐츠보다 서버에서 미리 생성된 HTML 콘텐츠를 더 빠르고 정확하게 인덱싱하기 때문이다.
당시 프로젝트는 빠르게 MVP(Minimum Viable Product)를 개발하고 시장에 출시해야 하는 상황이었다. 시간적 제약 속에서 기술 스택 선택은 매우 신중해야 했다.
SEO를 고려할 때 Next.js와 같은 프레임워크를 도입하는 것이 가장 이상적인 솔루션이었겠지만, 팀원들이 Next.js를 학습하고 적응하는 데 필요한 시간을 고려했을 때 급박한 일정과 맞지 않았다. 결국 익숙한 React를 사용하여 개발 속도를 높이되, 별도의 SSR 솔루션을 직접 구현하여 SEO 요구사항을 충족시키는 전략을 선택했다.
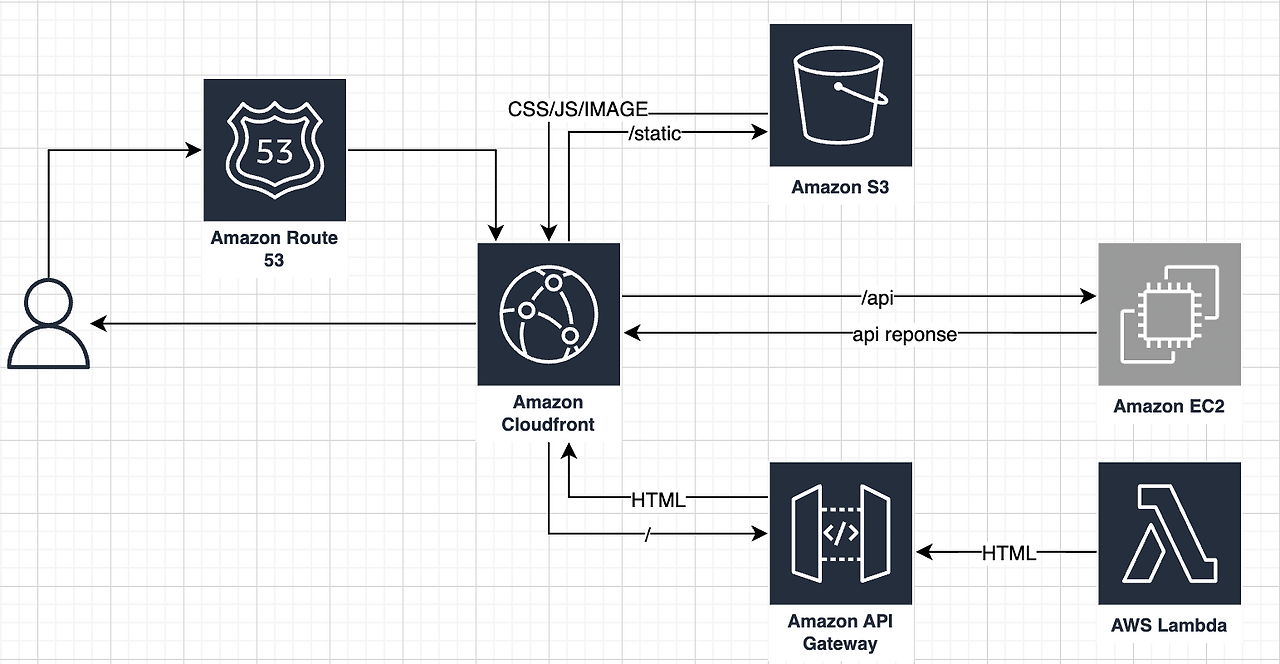
SSR을 구현하기 위해 다수의 AWS 서비스를 조합했다. 처음에는 이 복잡한 구조가 "배꼽보다 배가 더 큰" 상황처럼 느껴지기도 했지만, 글로벌 서비스를 지향하는 프로젝트의 특성상 각 서비스의 역할은 분명했다.
SSR을 위해서는 HTML을 생성할 서버가 필수적이다. 하지만 단순히 몇 개의 페이지를 서빙하기 위해 별도의 EC2 인스턴스를 관리하거나 Express 서버를 상시 가동하는 것은 리소스 낭비라고 판단했다.
이때 AWS Lambda가 최적의 대안이었다. 별도의 인프라 관리 없이 함수 단위로 코드를 실행할 수 있고, 필요할 때만 호출되는 방식은 SSR 작업에 매우 적합했다. 서버가 없는 상황에서 유지보수와 확장성을 모두 챙길 수 있는 합리적인 선택이었다.
React를 SSR로 서빙하는 것도, Lambda를 활용하는 것도 처음이었기에 머릿속에 순서를 그려가며 차근차근 진행했다.
Lambda가 실행할 핵심 로직은 **"컴포넌트를 HTML로 그린 뒤 응답하는 것"**이다. react-dom/server의 renderToString 메서드를 사용하여 이를 구현했다.
import React from 'react';
import { renderToString } from 'react-dom/server';
import App from './App';
export const handler = async (event) => {
const body = renderToString(<App />);
return {
statusCode: 200,
headers: { 'Content-Type': 'text/html' },
body: `<html><div id="root">${body}</div></html>`,
};
};
서버에서 내려준 HTML은 정적이다. 클릭 이벤트나 상태 관리 기능을 활성화하려면 클라이언트에서 Hydration 과정이 필요하다. React 18 기준으로는 hydrateRoot를 사용한다.
import React from 'react';
import { hydrateRoot } from 'react-dom/client';
import App from './App';
const rootElement = document.getElementById('root');
hydrateRoot(rootElement, <App />);
AWS CLI를 통해 빌드 파일을 업로드한 후 테스트를 진행했으나, 계속해서 index.mjs 파일을 찾을 수 없다는 500 모듈 에러가 발생했다.
원인은 파일 위치였다. 빌드 결과물이 dist/ 디렉토리 안에 생성되는데, Lambda는 루트 디렉토리에서 파일을 찾으려 했기 때문이다. 핸들러 경로를 dist/index.handler로 명시적으로 지정하여 문제를 해결할 수 있었다.
핸들러에서 react, react-dom 모듈이 필요하기 때문에 이를 Lambda Layer로 분리하여 관리했다. 코드와 종속성을 별도로 관리함으로써 배포 패키지 크기를 줄이고 관리 효율을 높였다.
여담으로, react-router가 Layer에 포함되지 않았음에도 정상 작동하여 의아했는데, 확인해보니 당시 환경에서 의존성 트리에 따라 함께 번들링되었거나 포함되어 있었던 것으로 보였다. 이처럼 의존성 관리의 투명성을 확보하는 것은 항상 중요하다.
모든 설정을 마치고 엔드포인트에 접속하면, 드디어 서버에서 렌더링된 HTML을 확인할 수 있다. 물론 처음에는 CSS나 JS 파일이 연결되지 않아 매우 썰렁한 화면이 반겨줄 것이다. CloudFront와 S3를 통해 정적파일을 연결하면 된다.
모든 설정을 마치고 작동하는 SSR 환경을 구축했지만, 솔직히 말하면 이건 완전한 SSR이 아니다. 현재 구현에는 몇 가지 근본적인 한계가 존재한다.
현재 구현은 react-dom/server의 renderToString 메서드를 사용하고 있다. 이 메서드는 React 18에서 레거시(Legacy) API로 분류되며, 최신 React의 강력한 기능들을 제대로 지원하지 못한다.
// 현재 사용 중인 방식 (Legacy)
import { renderToString } from 'react-dom/server';
const html = renderToString(<App />);
가장 큰 문제는 <Suspense> 경계를 만나면 즉시 렌더링을 중단하고 클라이언트로 렌더링 책임을 넘긴다는 점이다. 우리 프로젝트는 TanStack Query를 활용하여 서버 상태를 관리하고 있었고, 비동기 데이터 로딩 중에는 <Suspense> 태그로 감싸 폴백(Fallback) UI를 보여주도록 설계되어 있었다. 그런데 renderToString이 Suspense를 만나는 순간, 서버 렌더링을 포기하고 클라이언트에 모든 것을 맡겨버리는 것이다.
결과적으로 SEO를 위해 SSR을 구축했는데, 정작 중요한 데이터가 담긴 부분은 클라이언트에서 렌더링되는 아이러니한 상황이 발생했다.
React 18에서는 이러한 한계를 극복하기 위해 Streaming SSR을 도입했다. renderToPipeableStream(Node.js 환경) 또는 renderToReadableStream(엣지 런타임)을 사용하면, Suspense 경계마다 HTML을 점진적으로 스트리밍할 수 있다.
// 최신 방식 (Streaming SSR)
import { renderToPipeableStream } from 'react-dom/server';
const { pipe } = renderToPipeableStream(<App />, {
onShellReady() {
// 초기 HTML 셸(Shell)을 즉시 전송
pipe(response);
},
});
Streaming SSR에서는 Suspense가 **"여기서 멈춰라"**가 아니라 **"이 부분은 나중에 채울게"**라는 의미를 가진다. 초기 HTML 셸(Shell)을 먼저 보내고, 비동기 데이터가 준비되는 대로 해당 부분의 HTML을 추가로 스트리밍하는 방식이다. 이를 통해 초기 로딩 속도(TTFB)와 SEO, 사용자 경험을 모두 챙길 수 있다.
하지만 Lambda와 API Gateway 환경에서 이를 구현하려면 추가적인 작업이 필요했고, 당시 일정 내에서는 현실적으로 어려웠다.
프로젝트를 진행하고 시간이 지나면서 든 생각은, 차라리 처음부터 Next.js로 시작하는 편이 중장기적으로 훨씬 합리적이었겠다는 것이다.
| 항목 | React 직접 SSR | Next.js |
|---|---|---|
| 초기 학습 비용 | 낮음 (익숙한 React) | 중간 (프레임워크 학습 필요) |
| 구현 복잡도 | 높음 (인프라, 렌더링 직접 구현) | 낮음 (기본 제공) |
| 최신 기능 지원 | 제한적 (직접 구현 필요) | 완전 지원 (Streaming SSR, ISR 등) |
| 유지보수 | 어려움 (서버 리소스 직접 관리) | 쉬움 (추상화됨) |
| 성능 최적화 | 수동 (직접 구현) | 자동 (이미지, 폰트, 번들 최적화) |
React로 직접 SSR을 구현하면서 겪은 어려움들:
renderToString의 한계로 인해 완전한 SSR 구현이 불가능했다.하지만 이 과정이 헛되지 않았다고 생각한다. 직접 바닥부터 구현해봄으로써:
프로젝트 규모가 작고, 팀 학습 비용이 크게 부담되지 않는다면, 처음부터 Next.js를 선택하는 것을 강력히 권장한다. React로 직접 SSR을 구현하는 것은 학습 목적이나 특수한 요구사항이 있을 때만 고려할 만하다.